
For anyone choosing an AI platform — and anyone using one every day — this report answers one question: how much does enterprise governance cost in latency? We measured every request through Brutor’s full pipeline (auth, RBAC, governance, cost tracking, quota enforcement, guardrails, semantic cache, and routing) against the same models called directly. The answer is none of the speed your users feel — and that means security, control, and observability don’t have to be a trade-off you negotiate with your engineering team every quarter.
We tested the speed of the Brutor AI Gateway and compared it to competitive solutions. Here are the highlights:
Now let’s look at the benchmark results in detail.
The headline numbers, with the path that produced them.
Median (P50) overhead, taken across concurrency levels 1, 5, 10 and 20 — a more robust read than any single concurrency point. Each row tests the same upstream model both directly (client → provider) and through Brutor (client → Brutor → provider), so the delta is entirely the proxy’s contribution.
Methodology: LLMPerf, streaming chat completion, fixed prompt — 480 requests across 6 targets (OpenAI and Anthropic, direct and proxied) at concurrency 1, 5, 10 and 20. Run by the Brutor AI In-House Lab on June 15, 2026, against the same live providers. We first ran this benchmark in May 2026; this June re-run, with the more robust cross-concurrency median, returned the same conclusion — no detectable latency cost — and on the native pipelines it is now statistically indistinguishable from a direct call.
| Path | Median P50 overhead | How to read it |
|---|---|---|
| OpenAI (translation) | ≈ −80 ms | No cost — proxy ≤ direct |
| Anthropic (native pipeline) | ≈ −15 ms | No cost — proxy ≤ direct |
| Claude Code (native + beta headers) | ≈ +3 ms | Statistically zero |
| Anthropic (OpenAI-translated) | ≈ +75 ms | ≈ 5% of a ~1.5 s call — within provider variance |
A note on reading these numbers honestly: every figure is dominated by the live provider’s own latency (~1.5–2.0 s per call), and that latency swings more run-to-run than the proxy ever adds. In this run the direct OpenAI median moved ±400 ms across concurrency levels purely from provider variance — larger than any overhead we measured. That’s why several paths show negative overhead (the proxy “faster” than direct): warm, pooled HTTP/2 connections beat per-call TLS handshakes, and the noise floor is wider than the signal. The honest read is “no detectable cost” — not a precise millisecond budget. The one path with a small, consistent positive bias is Anthropic via the OpenAI-translation shim (≈ +75 ms, ~5%); if you want the lowest possible overhead on Anthropic, use the native pipeline, which measured at or below direct.
What that latency buys you.
That near-zero overhead above is the combined cost of everything below — the whole governance pipeline, running on every request. Most competing AI gateways charge more latency for fewer features.
JWT decode & API-key lookup
Bearer JWT or service API key validated, scope + expiry checked, tenant context resolved.
Resource group access
Workspace + ancestor-chain governance loaded; per-group model availability gate enforced.
Budget & rate limits
Per-tenant budget cap, per-model RPM/TPM, daily/monthly token ceilings — all atomic.
Behavioral rules
Temperature ceiling, context-window cap, banned-tool filter, mandatory system-prompt fragments.
PII & pattern scan
Bidirectional content-policy scan on prompt and response. Detect-only or block, per group.
5 strategies, configurable
Weighted, least-busy, latency-based, cost-based, usage-based — picked per workspace.
Wire-format normalization
Anthropic / Bedrock / Groq SSE → OpenAI-compatible chunks, transparently for the client.
Usage tracking
Token counting, cost calculation, audit row insert via background writer — never blocks the request.
Logs + traces + metrics
Structured proxy log, OpenTelemetry span, Prometheus counters. Every request, every time.
Per-mode policy
Audio voice/format whitelist, image size whitelist, video duration cap, embedding dim guard.
Tool + agent gating
Tool whitelist, approval workflow trigger, agent-to-agent delegation chain depth limits.
Vector lookup, infinite hit
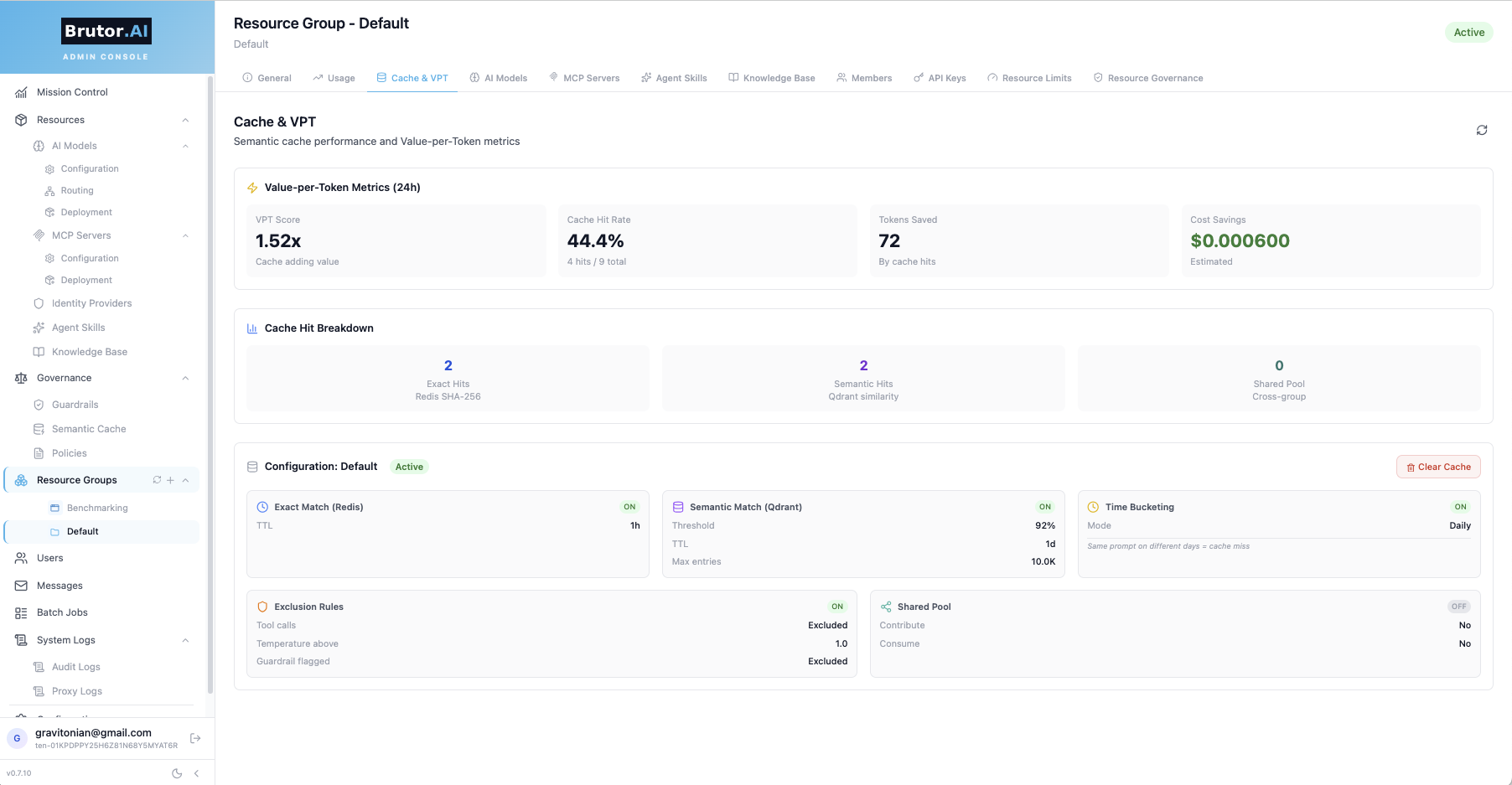
Two-layer cache (exact via Redis SHA-256 + semantic via Qdrant similarity). On hit: skip the upstream call entirely. Tenant-scoped, with per-group time-bucketing and exclusion rules. The dashboard tracks Value-per-Token — cost saved per dollar spent on tokens. The resource group pictured here scores 1.52× VPT on a 44.4% hit rate.
Why proxy CPU isn’t the bottleneck.
The end-to-end numbers above are dominated by network, TLS, and the provider’s own inference. To isolate Brutor’s own work, we run Criterion microbenchmarks against in-memory fixtures. Total proxy-internal CPU per chat request: under 5 ms.
How does Brutor compare to competition?
We could not do an honest comparison of Brutor against another AI gateway with the same feature set — simply because there isn’t another gateway with this combination of governance depth and Rust-native speed. We compared our gateway to leading competitors on the market who offer very different approaches to governance and have different architectures and feature sets. Here is what we concluded:
- Generic API gateways — built in C or Go. They promise single-digit-millisecond overhead and deliver it, because they don’t do anything AI-specific: no model routing, no guardrails, no semantic cache, no per-token cost tracking, no MCP or A2A awareness. If you adopt one for your AI traffic you still have to build the entire governance layer above it. Brutor sits at that same minimal-proxy latency floor — near-zero overhead on native pipelines — while shipping every one of those capabilities production-ready.
- Python-based AI gateways — built in Python on FastAPI. They have AI-specific features, but the runtime tax shows: recent published benchmarks from competing platforms put typical end-to-end overhead in the 100–500 ms range. That’s the kind of latency users feel; it’s the kind of latency that quietly inflates inference bills on streaming responses; it’s the kind of latency that makes engineering teams quietly route around the gateway for “real-time” use cases — which is exactly when governance matters most.
- Node-based and edge-worker AI gateways — built on Node.js or Cloudflare Workers. They narrow the latency gap, but the feature set narrows with them: logging, simple caching, basic fallbacks. Anything resembling enterprise governance still has to be built above.
Brutor AI Gateway delivers the full enterprise feature set at generic-API-gateway-class latency. The Rust runtime, async I/O, pooled HTTP/2 connections, and DashMap-backed concurrent state are why — and the consequence is that you don’t have to choose. You don’t trade governance for speed, you don’t trade speed for control, and you don’t have to defend either choice to the team that asks why their requests got slower the day audit logging turned on.
Run the benchmark yourself.
No vendor benchmark is worth anything if you can’t reproduce it. The same tool we used to generate these numbers ships with the proxy — reproduce it in under 5 minutes:
export BENCHMARK_OPENAI_KEY=sk-…
export BENCHMARK_ANTHROPIC_KEY=sk-ant-…
# 2. Point at your running proxy
export BENCHMARK_PROXY_URL=http://localhost:8100
export BENCHMARK_PROXY_API_KEY=sk_brutor_…
# 3. Run
cargo run –release –bin benchmark
Raw JSON + summary markdown drop into benchmark-results/ with timestamps. Every run is checked into the repo for trend analysis.
What these numbers mean for you.
Our benchmark testing and the resulting numbers address one of the main concerns IT managers have when looking into adopting an AI governance solution — the worry that putting governance, cost control, and guardrails between users and the model will slow things down. Our numbers say it plainly: governance doesn’t cost you speed, in any way users feel.
That changes the conversation. Governance stops being a tax that engineering teams quietly route around to ship something that feels fast. Security and finance stop having to choose between visibility and developer happiness. And your employees get on with making the most of AI — with the controls, audit trails, and cost guardrails your organization needs already running underneath, every request, every time.
If you’re evaluating an AI platform, this is one of the bars to measure against. Explore Brutor AI Platform and all its features ![]()
* Pass-through reliability: 100.0%. Zero proxy-introduced errors across 480 requests in the June 15, 2026 Brutor AI In-House Lab run. The only failures observed were upstream HTTP 429s from Anthropic at concurrency ≥ 10 — those occur at identical rates on direct calls, and Brutor faithfully forwards them.



